Как исправить «RuntimeError: CUDA недостаточно памяти»?
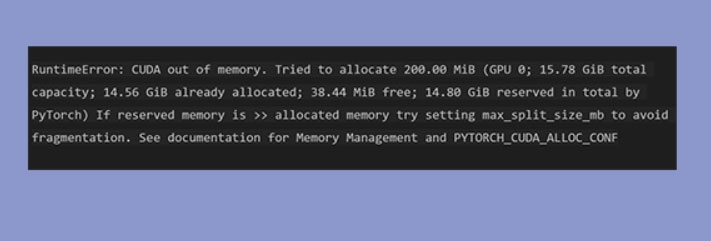
В сообществе исследователей и разработчиков PyTorch стал популярной средой глубокого обучения. В случае больших моделей или наборов данных пользователи могут столкнуться с неприятной ошибкой «RuntimeError: CUDA out of Memory».
Эта ошибка указывает на то, что память графического процессора исчерпана, что препятствует завершению глубокого обучения.
В этой статье мы расскажем вам о некоторых необходимых шагах, которые могут помочь вам устранить ошибку RuntimeError: CUDA out of Memory. Итак, без лишних слов, давайте начнем с руководства.
Что такое проблема нехватки памяти CUDA?
Это интегрированная аппаратная и программная технология, разработанная NVIDIA и расшифровывающаяся как Compute Unified Device Architecture.
Таким образом, графический процессор NVIDIA можно использовать не только для обработки изображений, но и для разработки C-компиляторов и выполнения других операций. Поэтому некоторые разработчики программ используют графические процессоры для машинного обучения и других целей.
Если вы используете PyTorch, Stable Diffusion или другую библиотеку машинного обучения, вы можете столкнуться с ошибкой нехватки памяти CUDA.
Что вызывает «CUDA нехватка памяти» в PyTorch?
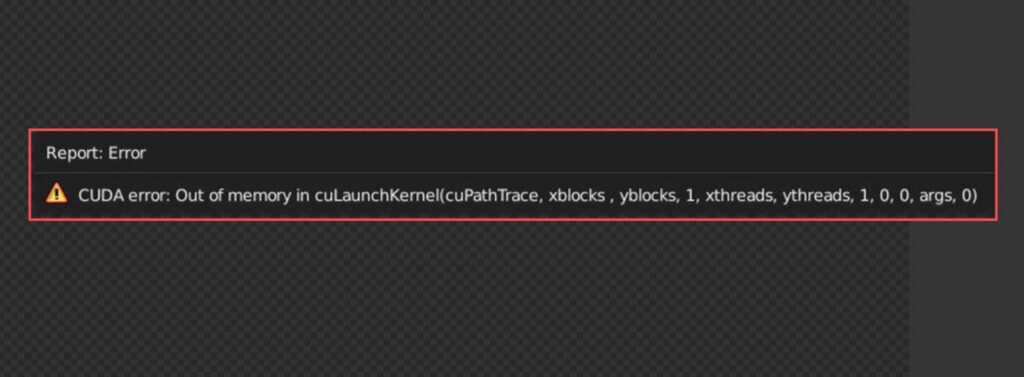
Python может отображать сообщение об ошибке «CUDA недостаточно памяти» по разным причинам. Вот несколько наиболее распространенных причин:
- Как правило, эта ошибка возникает, когда размер пакета слишком велик при обучении модели. Чтобы обрабатывать больше данных одновременно, вам необходимо увеличить размер пакета, что требует больше памяти на вашем графическом процессоре. Вы увидите ошибку «CUDA недостаточно памяти», если ваш графический процессор не может сохранить весь пакет.
- Вы также можете увидеть эту ошибку, если используете архитектуру большой модели. Когда большие модели потребляют память вашего графического процессора, производительность вашего графического процессора может серьезно снизиться.
- В вашей модели может быстро исчерпаться память, если вы не сможете освободить память после каждой итерации. Используйте функции управления памятью PyTorch, чтобы держать системную память под контролем и заранее освобождать переменные, когда они больше не нужны.
- PyTorch отслеживает все переменные, которым по умолчанию требуются градиенты. В случае больших моделей с большими партиями такое ведение журнала быстро потребляет всю память графического процессора.
- Программы, написанные на PyTorch, иногда могут вызывать утечку памяти графического процессора, то есть они выделяют память графического процессора, не освобождая ее после того, как они больше не нужны. В какой-то момент вашему графическому процессору может не хватить памяти, что приведет к появлению ошибки «Недостаточно памяти CUDA».
Теперь, когда ошибка «CUDA недостаточно памяти» обнаружена, давайте рассмотрим решения, которые могут помочь вам ее исправить.
Как исправить «RuntimeError: CUDA недостаточно памяти»?
Вот несколько простых методов, с помощью которых вы можете избавиться от проблемы RuntimeError: CUDA с нехваткой памяти:
Исправление 1: изменение размера пакета
Уменьшение размера пакета — лучший вариант, если вы используете уже существующий код или архитектуру модели. Разрезав файл пополам, продолжайте разрезать его до тех пор, пока ошибка больше не исчезнет.
Даже если вы установите размер пакета равным 1, если это все равно не поможет, возможно, придется решить другие проблемы, прежде чем большие размеры пакетов станут эффективными.
В PyTorch накопление градиента достигается за счет отсутствия вызова оптимизаторов.step() и оптимизатора.zero_grad() после каждого прохода вперед. Обратный проход происходит один раз каждые n, где n — количество шагов для накопления градиентов):
оптимизатор.zero_grad() # Явно обнуляет буферы градиента для i в диапазоне(num_mini_batches): inputs, labels = next(training_data) inputs, labels = inputs.to(device), labels.to(device) outputs = model(inputs) loss = критерий(выходные данные, метки) loss.backward() # Обратный проход для расчета градиента if (i+1) % накопления_шагов == 0: # Подождите несколько обратных проходовOptimer.step() # Теперь мы можем выполнить оптимизатор шагоптимизатор.zero_grad() # Сброс градиентов до нуля
Исправление 2: используйте тренировку смешанной точности
При использовании обучения смешанной точности ваша модель может быть обучена с использованием типов данных с более низкой точностью, что уменьшает объем используемой памяти.
Современные графические процессоры обладают большей мощностью, чем когда-либо прежде, поэтому обучение смешанной точности использует эту мощность для повышения производительности моделей без ущерба для точности.
Сокращая использование памяти и поддерживая производительность нейронной сети, он использует 32-битные и 16-битные типы с плавающей запятой для максимизации скорости и эффективности.
Многие части моделей глубокого обучения, такие как функции активации, не чувствительны к точности. Чтобы уменьшить объем памяти и ускорить время выполнения без ущерба для качества модели, можно использовать вычисления с половинной точностью (float16).
С пакетом torch.cuda.amp от PyTorch обучение смешанной точности становится относительно простым. В этом пакете amp.autocast — это менеджер контекста Python, который позволяет пользователю указывать, насколько точные операции следует выполнять.
модель = … оптимизатор = … масштабер = torch.cuda.amp.GradScaler() для входных данных, метки в данных: входные данные, метки = inputs.to(device), labels.to(device)Optimizer.zero_grad() # Запускает прямой проход с автокастом с помощью torch.cuda.amp.autocast(): выходы = модель(входные данные) loss = loss_fn(выходные данные, метки) # Масштабирует потери и выполняет обратный проход с использованием автоматического масштабирования смешанной точности Scaler(loss). Назад() Scaler.step(оптимизатор) Scaler.update()
Вы можете сократить использование памяти вашей модели на целых 50 %, используя половинную точность (FP16) вместо одинарной точности (FP32). Могут возникнуть проблемы со сходимостью слоев пакетной нормы PyTorch.
Чтобы решить эту проблему, убедитесь, что ваши слои пакетной нормы имеют тип float32, и не забывайте при необходимости выполнять преобразование между float32 и float16 между входными и выходными данными каждого слоя.
torch.backends.cudnn.benchmark = Истина torch.backends.cudnn.enabled = Истина
Исправление 3: используйте архитектуру меньшей модели
Выбор архитектуры модели с небольшим объемом памяти имеет решающее значение. Модели с большим количеством слоев или сложными структурами обычно потребляют больше памяти во время проходов вперед/назад, если у них много слоев или структур.
Использование архитектуры меньшей модели может быть хорошей идеей, если вы часто сталкиваетесь с ошибками «CUDA нехватка памяти».
Производительность не обязательно ухудшается, если вы выбираете более простую или меньшую модель. В Интернете доступен широкий выбор высокопроизводительных моделей с эффективным использованием памяти.
С точки зрения вычислительных ресурсов и точности модели MobileNet и EfficientNet обеспечивают хороший компромисс. Используя свертки с разделением по глубине, такие архитектуры могут уменьшить количество параметров, которые можно обучать, не жертвуя при этом точностью.
импортировать torch.nn как класс nn SimpleModel(nn.Module): def __init__(self): super(SimpleModel, self).__init__() self.conv1 = nn.Conv2d(3, 64, kernel_size=3, дополнение=1) self.pool = nn.MaxPool2d(2, 2) self.fc1 = nn.Linear(64 * 16 * 16, 10) # Отрегулируйте размер вывода в зависимости от вашей задачи
Исправление 4. Освободите неиспользуемую память графического процессора.
С помощью torch.cuda.empty_cache() вы можете вручную очистить память графического процессора в PyTorch. Эту функцию следует включить после пакетной обработки в соответствующем месте вашего кода.
оптимизатор.zero_grad() loss.backward() оптимизатор.step() torch.cuda.empty_cache()
Итак, вот как исправить ошибку RuntimeError: CUDA out of Memory. Мы надеемся, что это руководство помогло вам. Но предположим, что если у вас возникнут какие-либо вопросы или сомнения относительно этой темы, прокомментируйте ниже и дайте нам знать.
Дальнейшее чтение: